

The Hype Cycle – Reaching the Peak
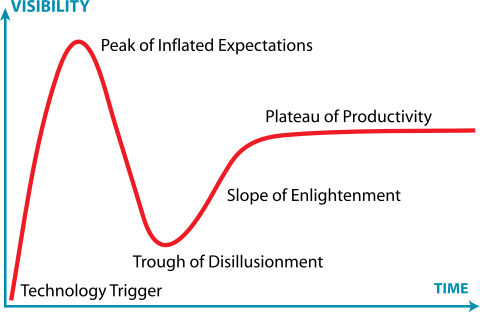

I think June 2024 will go down as the month when the Gen AI hype cycle reached its peak. There are several things that happened that indicated we have reached the peak of inflated expectations. I should point out at this point that I think this is a good thing. It means that businesses can start to focus on the real use cases for which Gen AI is potentially valuable. Just as importantly, it also means that businesses, and investors, can invest more into predictive, “traditional” AI and other growth areas otherwise starved of investment while the Gen AI Leviathan has been splashing around in the shallows, demanding attention.
The reason why these developments are significant, and not just blips on the road, is they indicate a heightened sense of awareness amongst end-users of Gen AI-enabled tools. People may forget these individual cases soon enough. But the idea that consumers are now sensitive to the risks of AI is an important moment. From now on, AI businesses will have to be more aware of the PR backlash.
In The News
Firstly, Apple announced its entry into the market, saying that its new phones will now include AI – “Apple Intelligence”. Can you see what they did there? On the face of it, this looks like a growth story, and in one sense, it is. Apple will incorporate its Apple Intelligence into apps, and ChatGPT will power it, creating a new platform for Gen AI.
However, Apple won’t be paying OpenAI for these searches, which suggests they see this as a commoditising tool, and not something that will differentiate in the future. In turn, that means OpenAI will be bearing the (not insignificant) cost for processing these requests. Therefore, the subscription model is vital, and OpenAI will be hoping to convert those Apple users to premium subscriptions.
But there are early indications that premium subscriptions are on the wane. ChatGPT monthly visits peaked at around 1.8 billion in early 2023. However, there was a notable drop to approximately 600 million visits per month by mid-2024. Whilst Open AI positions this as “fluctuations”, losing 2/3rds of your traffic in a year is a huge drop. Normally, this would attract a lot more scrutiny of the leadership team and the business model. But ChatGPT is not proving to be as “sticky” as investors had hoped. These fluctuations will definitely be something to watch.
The Consumer-Focused Challenges
Firstly, Microsoft had to recall its Microsoft Recall. This new AI-driven feature allows you to recall anything you do on your Microsoft Co-Pilot device. Which sounds great. But it does this by taking screenshots of your screen every few seconds, and then stores it on your device. However, it does this without encryption, so that anyone, or any tool, could get access to it. Quite how no-one considered this during product design and testing is unclear; Microsoft developed the tool under a different process to its usual user testing process. But punters did spot it, caused an uproar, and Microsoft recalled its own Recall plans. It probably plans to launch it again, but customers are now sensitive to this new risk.
Secondly, the Prince Charles Cinema in London had to cancel its premiere of the world’s first entirely AI-written film….because customers didn’t like the idea of a film with no (human) author. This may suggest that the market for fully-AI-scripted film is limited. This may also change how much film studios publicise how much they use AI. Whilst scripts and authorship might be part of human creativity, whether you need a second unit on location in the Atlas Mountains to film establishing shots might be how Sora fits in. But again, consumers are now sensitive to these questions, and might demand greater transparency.
However, the most high-profile consumer-facing failure was the removal of McDonald’s AI-driven voice AI ordering system (AOT – Automated Order Taking). Rather than speaking to a human at the drive-thru, you speak to an AI tool. But it made some big mistakes. For instance, it added bacon to ice cream (take note, Heston Blumental), and hundreds of unwanted chicken nuggets.
The real problem for this application is that McDonalds announced it in 2019 (before Gen AI came to prominence). So, it represents one of the early champions of Gen AI. For such a high-profile business to close a large-scale, mature programme is significant. Given its length of development, it seems unlikely this is down to underlying data quality issues, which is perhaps the most common problem with such models. Officially, McDonalds have said they will take some time to reflect on the future of voice-enabled AI. They will make a decision by the end of the year. But it has the classic hallmarks of the PR team kicking it into the long grass, and leaving it there.
The Not-So-Consumer-Facing Challenges
Adobe got in difficulty when it tried to update its terms of use for its Creative Cloud tools. This meant Adobe has access to anything created using those tools, so it can train its AI models on them. It has caused a backlash among its users, and forced Adobe to clarify its changes. To be fair, Adobe has moved fast to respond, and has clarified it won’t use other’s content to train its models. It’s more likely this is a silly own-goal at a hyper-sensitive time, rather than a cynical attempt to fleece customers. However, again customers have spotted it; we will wait to see how much client goodwill this has spent.
Perplexity, an AI unicorn that provides news summaries, has managed to live up to its name. In a detailed article, Wired, the digital business magazine, exposed Perplexity’s way of working. And it is, at the very least, perplexing. As the article shows, there are several elements to this. For Wired, the main issue is Perplexity just makes things up, even if it has access to the correct content.
This is indeed bad. But for me, the most concerning part is that it ignores the robots.txt standard. This is the way in which web sites tell web crawlers which parts of the site are not publicly available. So, it can get past paywalls and access sensitive and/or subscription only content, without the right privileges, and without paying.
For some (the AI maximalists), this is just a minor hiccup on a start-up’s growth trajectory. For others, this is a fundamental part of how Perplexity delivers its proposition, and is core to the business model. It’s also deliberately deceptive, because it uses an undeclared IP address to do the secret crawling, so web sites can’t block it. If General Search AI’s business model is founded on breaking piracy law and not paying for content access, then it’s not going to be sustainable.
The counter argument to this copyright / fair use / piracy concern remains – “isn’t it just like every other author reading other people’s stuff, before starting writing themselves”. To which the answer is of course no. Because firstly, authors will have paid for those other books. And secondly, they haven’t deliberately worked out a way to avoid paying, nor broken the well-established convention for respecting restricted content (like borrowing books from a library, but with no intention of ever returning them). We still await the big legal showdowns on piracy and copyright. We might start getting decisions on some of these later in the year.
But there was one AI-related legal decision of note in June. After a 13 year legal battle, Mike Lynch, the founder of Autonomy, the British AI company bought by HP, was found not guilty of fraud in a US court in June. HP cried foul and sued Autonomy and its executives almost as soon as they bought the business. Lynch has been fighting ever since. This was a criminal trial, brought by the US Government, so it’s very significant that he was found not guilty. “This verdict closes the book on a relentless 13-year effort to pin HP’s well-documented ineptitude on Dr Lynch,” Lynch’s lawyers said. “Thankfully, the truth has finally prevailed.”
What didn’t happen in June
(Or, perhaps, why we might not have reached the peak yet)
The hidden piece of the AI jigsaw for which we will have to wait is around energy and water consumption. At the moment, this is still an industry secret that the data centre industry is aware of. But very few outside are. More importantly, currently businesses don’t need to report on Scope 3 emissions, which, for the data and cloud industry, is where the vast (around 95%) majority. So, cloud, data storage and AI businesses can currently claim to be carbon neutral, by ignoring Scope 3 (or reality, in other words).
To put this in context, the data centre industry is currently, officially, responsible for about 3% of global energy consumption. That’s the equivalent of the entire aviation industry. The reality is that it’s probably much, much larger than that. Famously, Chat GPT3 needed the equivalent energy of an entire nuclear power station just to train itself. What GPT4, GPT4o or Sora have taken is not public knowledge as yet.
At the moment, no-one other than a few data environmentalists cares about this. But European businesses will have to report on all emissions as part of the CSRD from January 2025. It’s at this point that businesses will have to accurately report on Scope 3 as well; when the CFO has to report to the market what is going on, that’s where that shift could occur. We will have to wait and see as to whether the public actually care about energy and water consumption, so they can watch AI-generated cat videos. But science education will be an important factor; podcasts like this might be the tip of the iceberg.