September Fun Fact

Our monthly dose of David’s fun fact is here for you to enjoy. Do you know where algorithm originates from – watch this and you soon will do!


Our monthly dose of David’s fun fact is here for you to enjoy. Do you know where algorithm originates from – watch this and you soon will do!


We are living in one of the most exciting times in terms of technological developments. As data processing and machine learning advances, the boundaries of its application are widened. The ever-evolving branch of computational algorithms are considered the “work horse” in many organisations across all industries. As alluded to by the title, this blog will briefly explore the applicational possibilities of machine learning with primary focus given to the financial sector.
Natural Language Processing (NLP) is a field that has heavily developed over the last decade. What started out as text classification has progressed to text understanding and most recently, text generation; whereby a robot is able to write an entire article.
Regarding the financial sector, the ability to generate text from data inputs has been utilised to form reports, increasing efficiency and reducing liability of human error. Further progress has been seen with image recognition, where information can be depicted and translated into a lexical format. Application for this can be found predominantly within insurance. For example, digital assets such as satellite imagery can be used to investigate potential fraudulence in insurance claims.
Processes require use of reinforced learning whereby human input in the form of punishment and reward to train models. These are implemented in some cases by inputting annotated images thousands of times so the program can recognise specific objects or trends. An example of this can be found in the Alpha Go program; the first computer program to defeat the Go world champion (professional human gamer). Furthermore, data science within trading has provided gateways to generate competitive advantage. More specifically, reinforced learning has been utilised by leading firms to create advanced signals, maximising financial performance when block trading. Due to the progressive nature of the technology, algorithms can learn from themselves over time by understanding previous signals.
Lastly, recommender systems provide companies with the intelligence needed to target specific audiences at the appropriate time. An example of this being, during the lockdown period many households decided to purchase pets. Data driven from consumer context, behaviour, needs, and preferences enabled pet insurance brokers to target new pet owners with intelligent, personalised offerings. However, it is important to note that recommender systems can be controlled so that unwanted spikes in trends do not skew or change results.
In summary, we are amidst an exhilarating time where machine learning and data utilisation is advancing rapidly. With its application ever expanding, we endeavour to seek new ways in which data can drive positive change to businesses and individuals across the globe.
Watch our summary by clicking here: https://share.vidyard.com/watch/wy1WMhgh2sNSsF3TfPfjRc
Click to arrange a discussion with David Ellis (MD) david.ellis@station10.co.uk or Nick Willis (Commercial Director) nick.willis@station10.co.uk
Book into our next event on the 22nd October as we further explore ‘The Art of The Possible’ here. The Art of the Possible – for you and your business – Station10

In the last few weeks, the leaders of tech giants such as Facebook and Google have headed to Brussels as the European Commission debated and then revealed a draft of its planned new rules surrounding data and artificial intelligence as well as sharing proposals focussed on driving growth and innovation in the region.
When it comes to policy, Europe often sets the standards that the rest of the world adapt and adopt, which has often been the case with data privacy regulations. This is most likely why leaders from Silicon Valley are paying such close attention; as tech companies are increasingly scrutinised, it’s in their interest to be a part of the debate which could form how they operate in the future.
The EC wants to prevent data misuse whilst also building the technology platform for society to reap the benefits of being data driven.
“Currently, a small number of Big Tech firms hold a large part of the world’s data”
With statements such as this, it is clear that the draft policies released by the EU last week are taking aim at US tech giants. To compete with this, the new policies aim to create “a single European data space”, making the EU a more significant player on the global data stage, focusing on fairness and transparency in a bid to differentiate itself from its main competitors in this field – the US and China.
So, what’s on the menu?
Data Sharing
To achieve its goal of creating a single market for data, the EU’s first plan to improve its standing on a global stage is to foster the commercial sharing and processing of data. The ultimate goal is to provide the infrastructure for EU companies to be able to flourish to the same scale as US ones, such as Facebook, for example.
It wants to make data available to entrepreneurs to use as the basis for startups and new innovations. Of course, in return, the EU expects that companies build tech that is in line with its beliefs of fairness and transparency. By ensuring this, it’s hoped that citizens will become more comfortable with the use of their personal data.
Artificial Intelligence
By some, AI is believed to be a truly transformative technology, and potentially even critical to economic survival. Others express concern stemming from privacy issues and the potential impact AI will have on the future of work.
In the US, huge tech companies have been leading the way. In China, it’s the government pushing forward with new technologies. However, Europe is perceived to be falling behind. So, in the new proposals, the need to catch up is a prominent topic.
A huge focus is on investment. The EU proposed spending of over $20billion annually for a decade to support new data ecosystems that can aid AI development. Additionally, in line with the rest of the announcements, the EU plans to differentiate itself by creating an environment where AI investment is an attractive proposition for companies, but also not a concern for individuals. The proposals focus on the need to develop rules that prevent problems including bias and discrimination. A particular emphasis was also placed on “high risk” uses of AI, such as in health care and transportation. These areas will face much tougher scrutiny.
Facial Recognition
A specific area of focus in the proposals was facial recognition, an increasingly controversial technology, which the EU confirms it will continue to study. Of course, there are some uses of facial recognition that are pretty low risk, such as unlocking a phone, but the EU’s reports make it clear that the technology has the potential to pose human rights risks.
At the moment, the use of facial recognition is allowed in most cases, but the EU is proposing a debate on where the technology should be regulated or even banned in some cases. It looks likely that we will see some restrictions, on the grounds of a person’s right to privacy, the processing of data without consent, and potential discrimination and bias.
Although no guidance or explicit warnings have been made at the moment, these proposals come in the same week that the EU’s digital chief, Margrethe Vestager, says that she believes that facial recognition requires consent under GDPR. Whilst the EU did cancel its plans to completely ban facial recognition temporarily, Vestager stated that new legislation is coming, but in the meantime, EU member states can make their own decisions on the technology whilst further investigations are undertaken.
Conclusion
The EU’s view on the AI debate seems to be focussed on a move away from the US approach, where companies have been left to develop technology with little scrutiny. By taking this more hands on approach, the EU hopes to be able to set clearer boundaries on data privacy, but also, through an ambitious investment programme, encourage innovation and advancements in technology.
Following last week’s announcements, the European Commission has begun a 3 month consultation inviting comments on the plans. We should hopefully see formal propositions for new legislation as soon as the end of the year. Following on from Boris Johnson’s announcement that the UK would seek to move away from the EU’s data protection rules and establish its own, it will be fascinating to see how the EU’s new proposals impact that stance and alter the future UK/EU relationship surrounding technology and privacy.

The current data science landscape must appear extremely confusing for companies starting to explore how to better use their data today.
Some applications of Artificial Intelligence have the potential to disrupt entire industries and investors excited by that prospect are channelling capital towards related projects. Obviously, many businesses try attracting a share of that manna and use their powerful marketing voices to do so.
Those marketing messages are probably the main source of confusion. Artificial Intelligence and Machine Learning are complex topics that are not always fully understood by marketers, journalists and other analysts.
The same publications, in their effort to attract money, also instil a sense of urgency. Their message is that it is already late and that something has to be done immediately…
In this post, we try reducing the confusion by coming back to the definitions of some of the main buzz words. We also attempt to calm down those thinking that they are too late by coming back to the history of some of those fields.
Definitions
Let’s start with some high-level definitions from generalist sources.
Artificial Intelligence (AI): “The theory and development of computer systems able to perform tasks normally requiring human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.” (Oxford Reference)
Machine Learning (ML): “A type of artificial intelligence in which computers use huge amounts of data to learn how to do tasks rather than being programmed to do them.” (Oxford Learner’s Dictionaries)
Deep Learning: “A class of machine learning algorithms that uses multiple layers to progressively extract higher level features from the raw input.” (Wikipedia)
Note the relationships implied by those definitions. Deep Learning is a form of Machine Learning and Machine Learning is a type of Artificial Intelligence. That relationship is clearly illustrated by experts in the field.
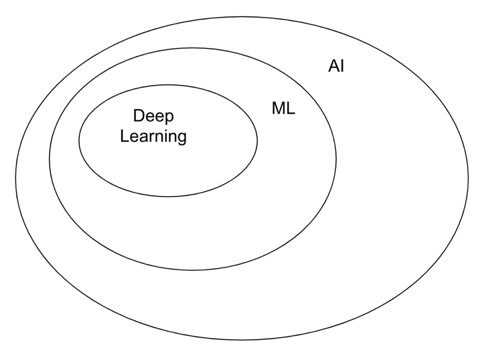
It is interesting to note how many articles are opposing some of those techniques and totally missing the point described above. By definition, your ML cannot be more AI than mine! Also, no one is implying any form of hierarchy between different techniques. The tools you will need to tackle your business problems are dependent of the nature of the problem and the available data.
I do not intend to focus on the wider AI in this post. However, I can point you to the rule-based expert systems of the 1980s as an example of what AI without ML looks like. Think about a system that could make diagnostics based on pre-programmed rules related to symptoms.
We can actually start from here to further explain what ML is and how different it is from those traditional programmed systems.
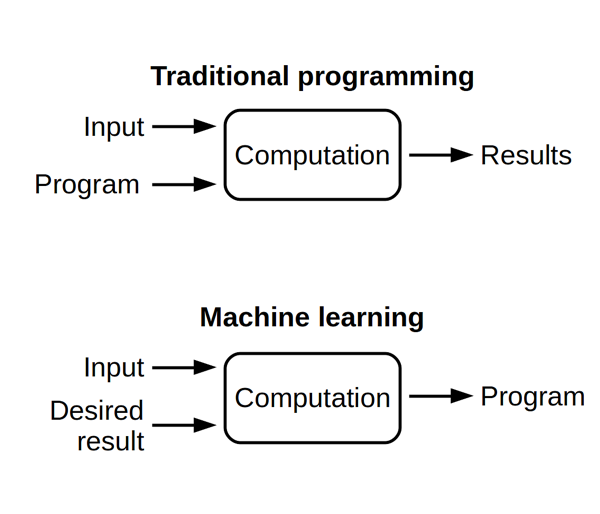
This diagram clearly illustrates what the Machine Learning revolution is all about. Traditionally, programmers had to write programmes fully describing the computations that the machine was supposed to apply to some input data to get the expected results.
Machine Learning is based on the capability of a system to consume input data and data about expected outcomes, to uncover the relationships between the two and to express them as a form of programme that we call a model. No more need for the programmers to think about all the possible rules, the chosen ML algorithm will learn them.
That is a revolution, but one which has started a long time ago!
History
First of all, it is important to remember that much of the Machine Learning we use today is still relying on techniques borrowed from statistics. Think about Ordinary Least Square regression we owe to 18th century mathematicians Gauss and Legendre! But let’s move to a more contemporary vision.
In the 1940s, a combination of new ideas coming from different fields laid the groundwork for the emergence of Artificial Intelligence. Neurology demonstrated that the brain is an electrical network of neurons, cybernetics formalised “the scientific study of control and communication in the animal and the machine” and Alan Turing showed that all computation can be described digitally.
It is finally in 1955 that John McCarty, an American Computer Scientist, coined the term Artificial Intelligence. Arthur Lee Samuel, who developed self-learning Checkers programmes, came with the term Machine Learning in 1959.
The last wave of innovation came in the 2010s when the increase in computing power allowed to fully exploit the Backprogation Algorithm (1986, but based on work started in the 1960s) that describes how to efficiently train Artificial Neural Networks with many layers – that is Deep Learning.
(Note: “Learning Internal Representations by Error Propagation”, Rumelhart, Williams and Hinton (1986))
Deep Learning allowed for the progress in image recognition and Natural Language Processing (NLP) witnessed over the last decade and spectacularly exploited by the major internet companies. And obviously, that wave of successes led to the frenetic marketing activity mentioned earlier.
Where does that leave us?
We are lucky to work in a field that is constantly evolving and where new progresses in Computing and Machine Learning slowly filter into commercial applications. We have a rich palette of tools we can choose from, but we have to keep in mind that the most important question is a business one. What business problem are we trying to address? It is only then that questions about what data to collect or what techniques to use become relevant.